
A few days ago, we annouced a major update to Diffy and briefly mentioned the introduction of a powerful Request Transformation feature. Before we dive in, here's a bit of context on why we need different kinds of request transformation.
As your APIs evolve, you inevitably introduce breaking changes that make old requests (served by older versions of your APIs) incompatible with newer versions of your APIs. If the new API is genuinely doing something different than the old API then the old requests are no longer useful for any kind of testing and you can safely ignore them.
That said, it is truly unfortunate that you can't use old requests to test newer versions of an API when the underlying purpose of the API hasn't changed. You still want to know that the new API behaves like the old API - only now you need to "touch up" your old requests to turn them into new requests.
Here's different kinds of touch ups you can perform with Diffy 2.0:
Header Transformation
Many of customers mirror production traffic to Diffy to catch API regressions in their services. Replaying production traffic in test environments can lead to some problems like auth tokens not working in test environments - you need to override the headers in order for the traffic to be consumable in your test environment. e.g.
request => {
request.headers['auth-token'] = 'test-environment-token'
}
URI Transformation
Sometimes, the new code you want to test is expected to have the same functionality as the old code with a modified URI structure. Modified URI structures in the new code mean that old URI structures sampled from production environments will lead to 404 errors. In order to successfully replay and verify the expected behavior of the new code, you need to transform the old URI structures to new URI structures before sending the request to your new code.
request => {
// transform /api/1/* to /api/2/* e.g.
// /api/1/products/3465 to /api/2/products/3465
if(request.uri.startsWith('/api/1/')){
request.uri = request.uri.replace('/api/1/','/api/2/')
}
}
Body Transformation
Making schema changes to your APIs involves mapping old fields in your old code to new fields in your new code. This situation requires for you to rewrite the body of requests with your old schema to new your schema so that the request becomes consumable to your new code. With this necessary transformation, your new code will not be able consume production traffic.
request => {
// We have just refactored our code such that product objects that were previously consumed as
// { name: string, image_url: string }
// are now consumed as
// { id: string, imageUrl: string }
// i.e. the field 'name' has been renamed to 'id' and
// 'image_url' has been renamed to 'imageUrl'
request.body.id = request.body.name
request.body.imageUrl = request.body.image_url
delete request.body.name
delete request.body.image_url
}
Bonus - Advanced Security and PII Scrubbing
Your production traffic contains sensitive data that can not be exposed to your test environments. This requires the requests to be scrubbed before being sent to your test targets.
request => {
// We want to redact an email deep inside the body of the request
request.body.user.email = 'redacted@email.com'
}
The above examples are simplified pseudocode for readability but the key takeawaye is that you can implement pretty much any transformation you can imagine to your request given the power of a scripting language at your fingertips.
Request Transformation
With Diffy, you can now inject request transformation logic in 4 places:
All - these transformation will be applied to requests being sent to candidate, primary and secondary.
Candidate - these transformation will only be applied to the requests received by candidate.
Primary - these transformation will only be applied to the requests received by primary.
Secondary - these transformation will only be applied to the requests received by secondary.
You can pick the places that you want to inject your transformation via the UI and then write and save the transformation:
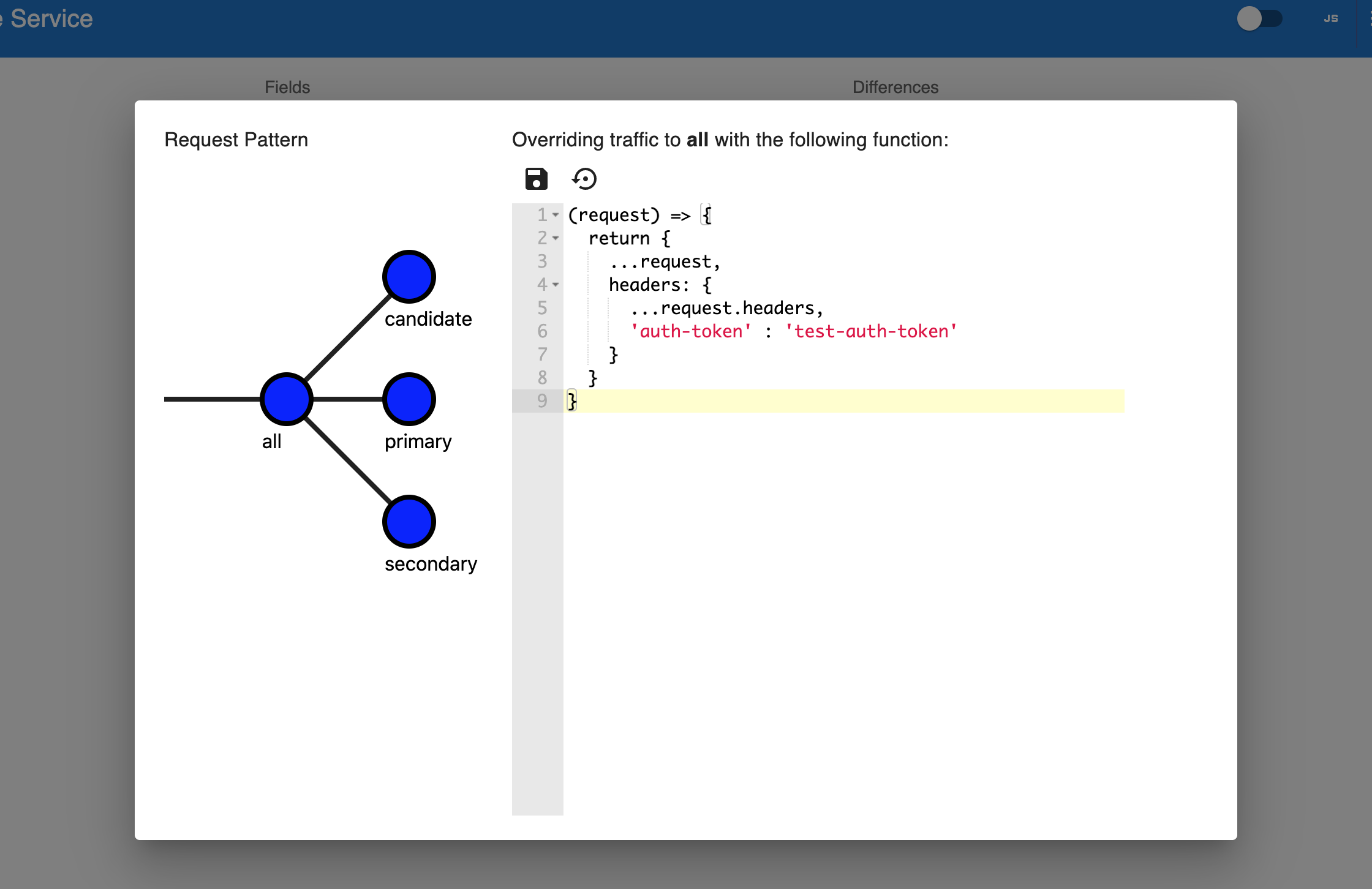
That's it! You can now send traffic to your Diffy instance and Diffy will apply your transformations to the requests before sending them off to the targets.
If you have any follow up questions please feel free to reach out to us via our Discord server or at isotope@sn126.com.

 Bending space time for the greater good of software quality
Bending space time for the greater good of software quality
